Introduction:
Hey everyone! I’m excited to walk you through my recent data analysis project on diabetes. You can find all the code and materials on my GitHub repository 💻. I’ve also put together a detailed presentation that you can view as a PDF , and the source dataset through the mentioned link.
Diabetes is a complex condition, and this project aimed to break down the key factors involved and explore the potential of machine learning to predict its occurrence. I used Python and libraries like pandas , scikit-learn, and matplotlib to analyze patient data and uncover some really interesting insights. Let’s dive in!
Project Overview: Setting the Stage
This project’s main goals were to:
- Understand the various factors that contribute to diabetes.
- Explore how well we can predict diabetes using data.
- Extract information that could be useful in real-world clinical settings.
To do this, I worked with the “Healthcare-Diabetes.csv” dataset, which includes a range of patient information. Key features I looked at included:
- Glucose levels 🩸
- BMI (Body Mass Index)
- Age
- Blood Pressure 🩺
- Insulin levels 💉
- Genetic predisposition (Diabetes Pedigree Function)
- And, of course, the “Outcome,” which tells us whether a patient has diabetes (1) or not (0). 📊
I used a combination of techniques, including:
- Exploratory Data Analysis (EDA) to visualize the data. 📈
- Statistical analysis to find relationships between variables. 🔢
- Machine learning to build predictive models.
Key Findings: What the Data Revealed
Here are some of the most important things I discovered:
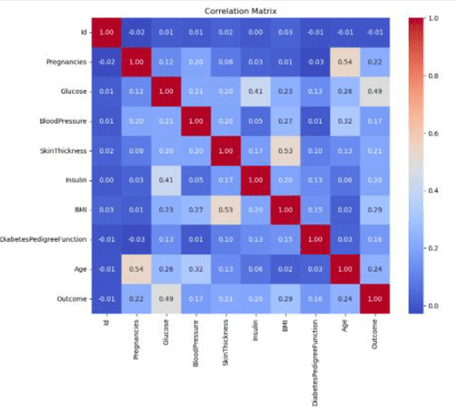
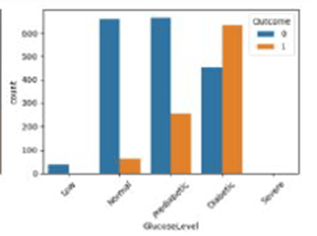
- Glucose is King: 👑 Glucose level consistently emerged as the strongest single predictor of diabetes. In fact, the correlation matrix showed a 0.49 correlation between Glucose and Outcome, which was higher than any other single factor. This confirms what we already know clinically: glucose is a primary diagnostic factor.
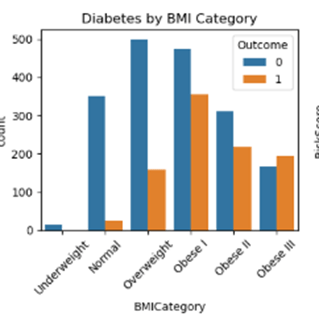
BMI Matters (A Lot): BMI is also a major player. The data clearly showed that higher BMI is strongly associated with diabetes. For example, the “Diabetes by BMI Category” chart showed that diabetes prevalence jumps significantly in the “Obese” categories
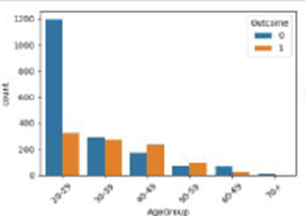
Age Plays a Role: Older age is another contributing factor. The data showed a trend of increasing diabetes prevalence with age, particularly up to around 50-59. 📈
The Power of Combined Factors: Interestingly, the interaction between Glucose and BMI (Glucose_BMI) was even more predictive than either alone. This highlights how these factors work together to increase risk.
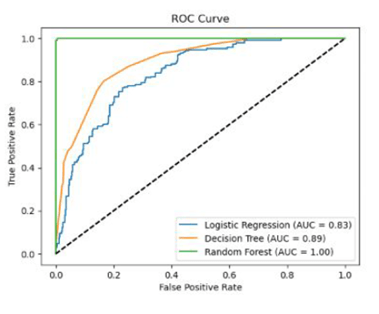
Model Performance: The machine learning models I built were able to predict diabetes with impressive accuracy (AUC-ROC score of 0.999 in cross-validation!). 🚀 However, this also raised a flag for potential overfitting, which I addressed through careful validation.
Clinical Takeaways
These findings have important implications for how we approach diabetes:
- Early Detection: Accurate prediction models could help identify high-risk individuals early.
- Lifestyle Interventions: The strong link between BMI and diabetes reinforces the importance of weight management.
- Personalized Risk Assessment: Considering combined factors like Glucose_BMI might lead to more personalized risk assessments.
I’m always open to discussion and feedback, so please feel free to reach out! 💬




Leave a comment